Tecniche di Bootstrap
Analisi Dati e Statistica, 2025–26
![]()
Ultimo aggiornamento: 17/06/2026
Bootstrap
\(\renewcommand{\hat}[1]{\widehat{#1}}\) \(\renewcommand{\tilde}[1]{\widetilde{#1}}\) \(\renewcommand{\theta}{\vartheta}\)
To pull onself up by one’s bootstraps significa letteralmente sollevarsi da terra tirandosi per le cinghie degli stivali
In generale, significa costruire qualcosa da risorse apparentemente minime o inesistenti
In statistica, significa ricostruire una popolazione da un semplice campione

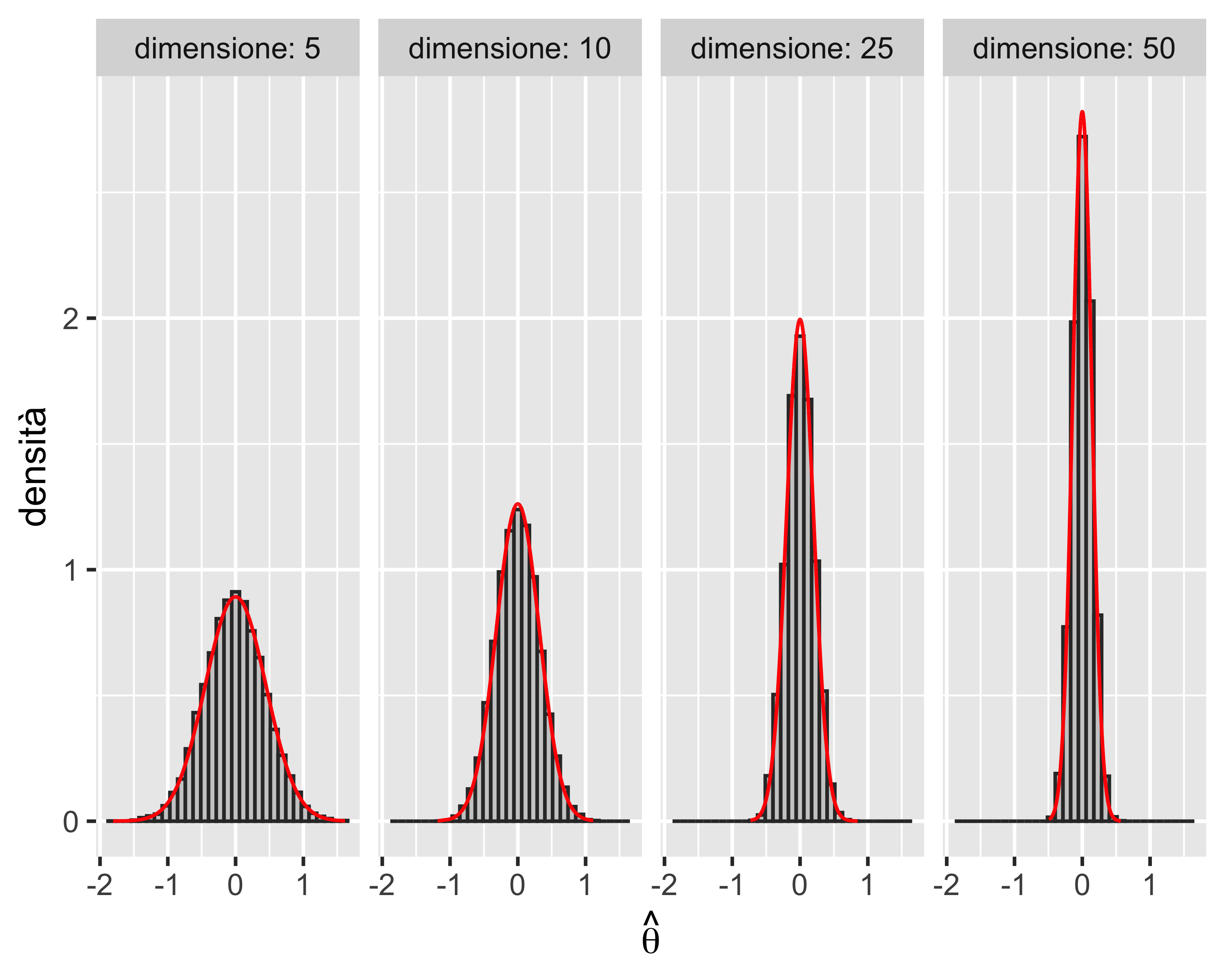
Esempio: media campionaria, distribuzione uniforme
Se il campione proviene da una distribuzione non-normale (ad esempio uniforme) allora, grazie al teorema del limite centrale, la distribuzione della statistica campionaria è asintoticamente normale, cioè \(G(\theta)\rightarrow\mathcal{N}(\theta, \sigma^2/n)\) quando \(n\rightarrow +\infty\).
Ripetiamo l’analisi sopra fatta per il campione normale
Questa volta gli istogrammi, come previsto dal teorema del limite centrale diventano gradualmente più normali all’aumentare del numero di elementi di ciascun campione
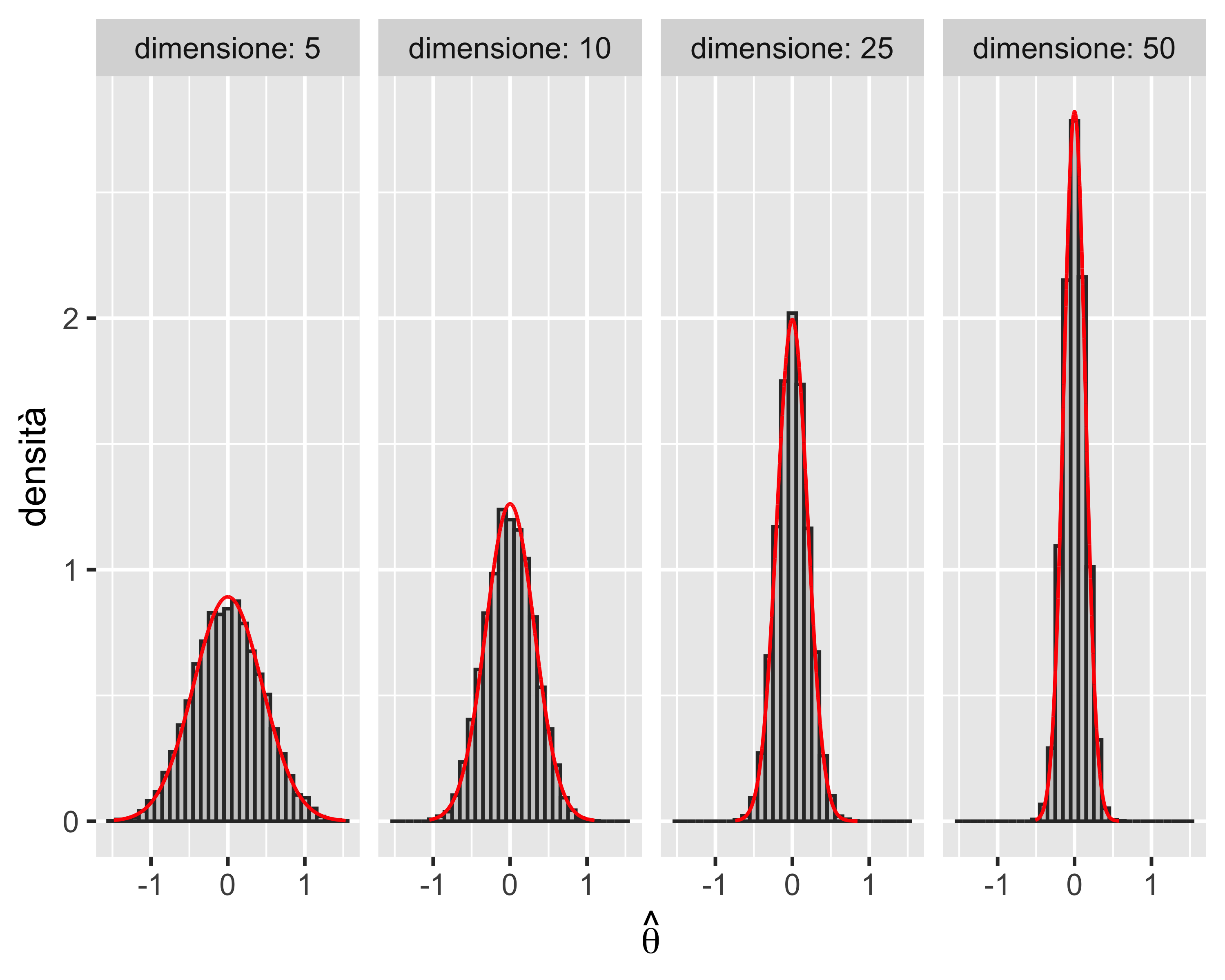
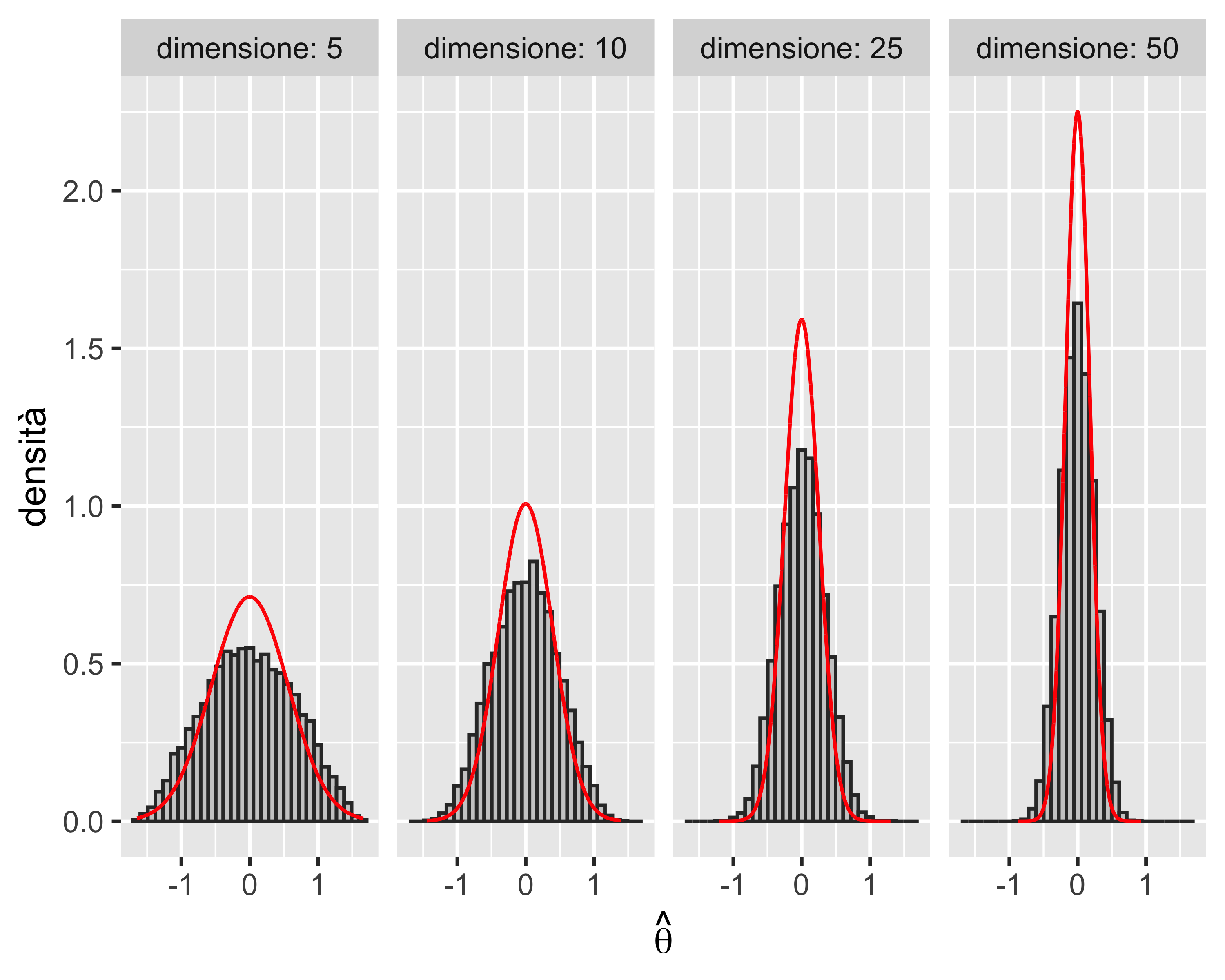
Esempio: mediana campionaria
Consideriamo la mediana \(\tilde x\) come statistica, a partire da campioni uniformi
Si può dimostrare analiticamente come in questo caso la distribuzione campionaria di \(\hat\theta=\tilde x\) tende ad una distribuzione normale \(\mathcal{N}(\theta, 1/(4nf(\theta)^2))\), dove \(f(\cdot)\) è la PDF della normale standard, quando \(n\rightarrow +\infty\)
In questo caso, la convergenza è ancora più lenta della convergenza della media su un campione uniforme
La convergenza è comunque garantita dal teorema del limite centrale
Esempio
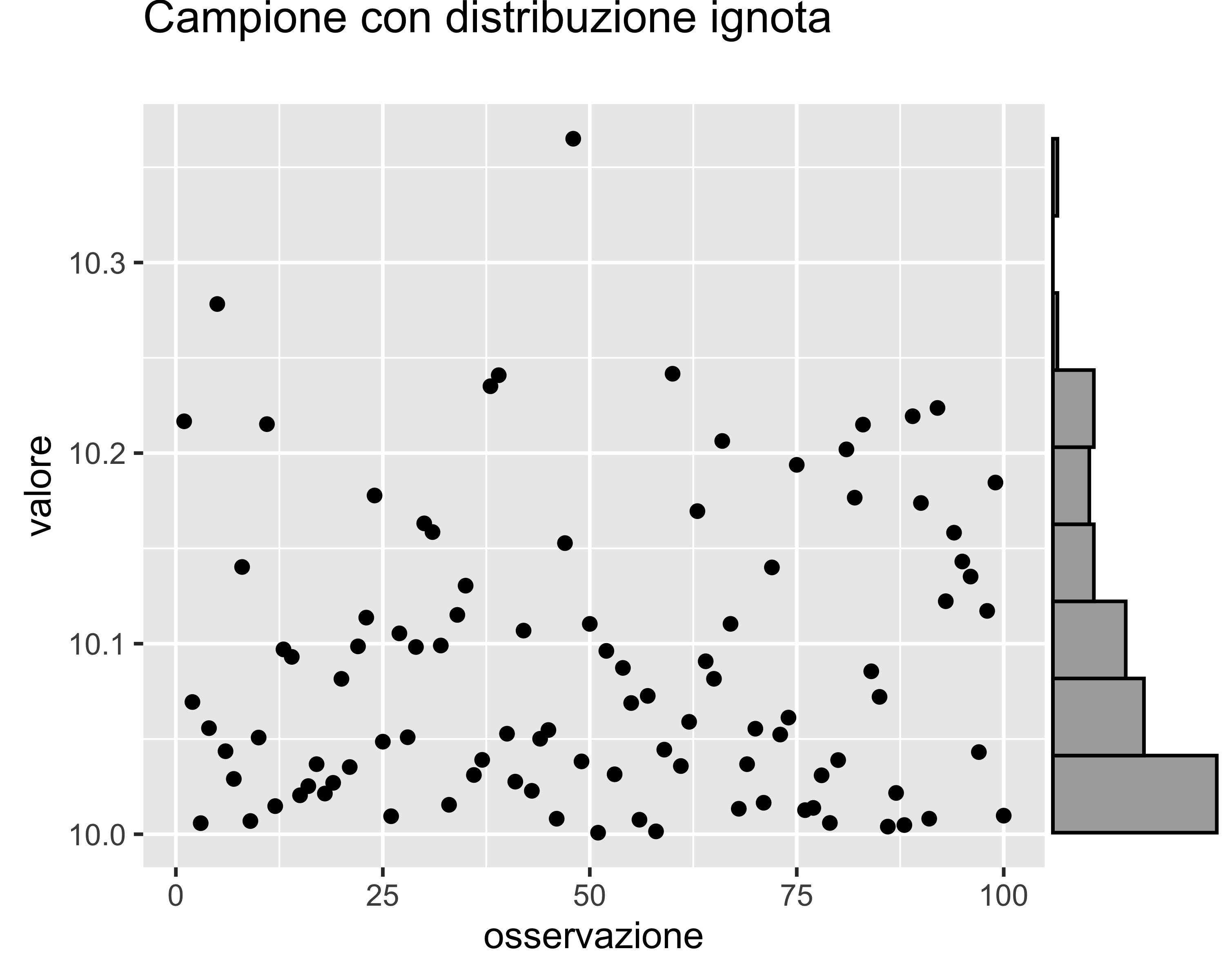
Consideriamo un campione di \(n=100\) elementi provenienti da una popolazione con distribuzione ignota
Dal grafico è evidente che la distribuzione non è normale
Vogliamo calcolare il valore atteso della media campionaria e il suo intervallo di confidenza
NOTA: se valesse l’ipotesi di normalità, l’intervallo di confidenza potrebbe essere calcolato dal T-test a un campione
Esempio
Costruiamo un campione di boostrap ricampionando \(R=5\times 10^{4}\) volte il campione originario, calcolando \(R+1\) volte la media campionaria
Riportiamo in istogramma le \(R+1\) stime della media
Il valore atteso della media è \(E(\bar x)=\bar{\hat \theta} = 10.0888\)
L’intervallo di confidenza per la media al 95% è calcolato dai quantili empirici di \(\hat \theta\): \[ L = Q^-(\hat \theta, (1-0.95)/2),~~~U = Q^+(\hat \theta, (1-0.95)/2) \]
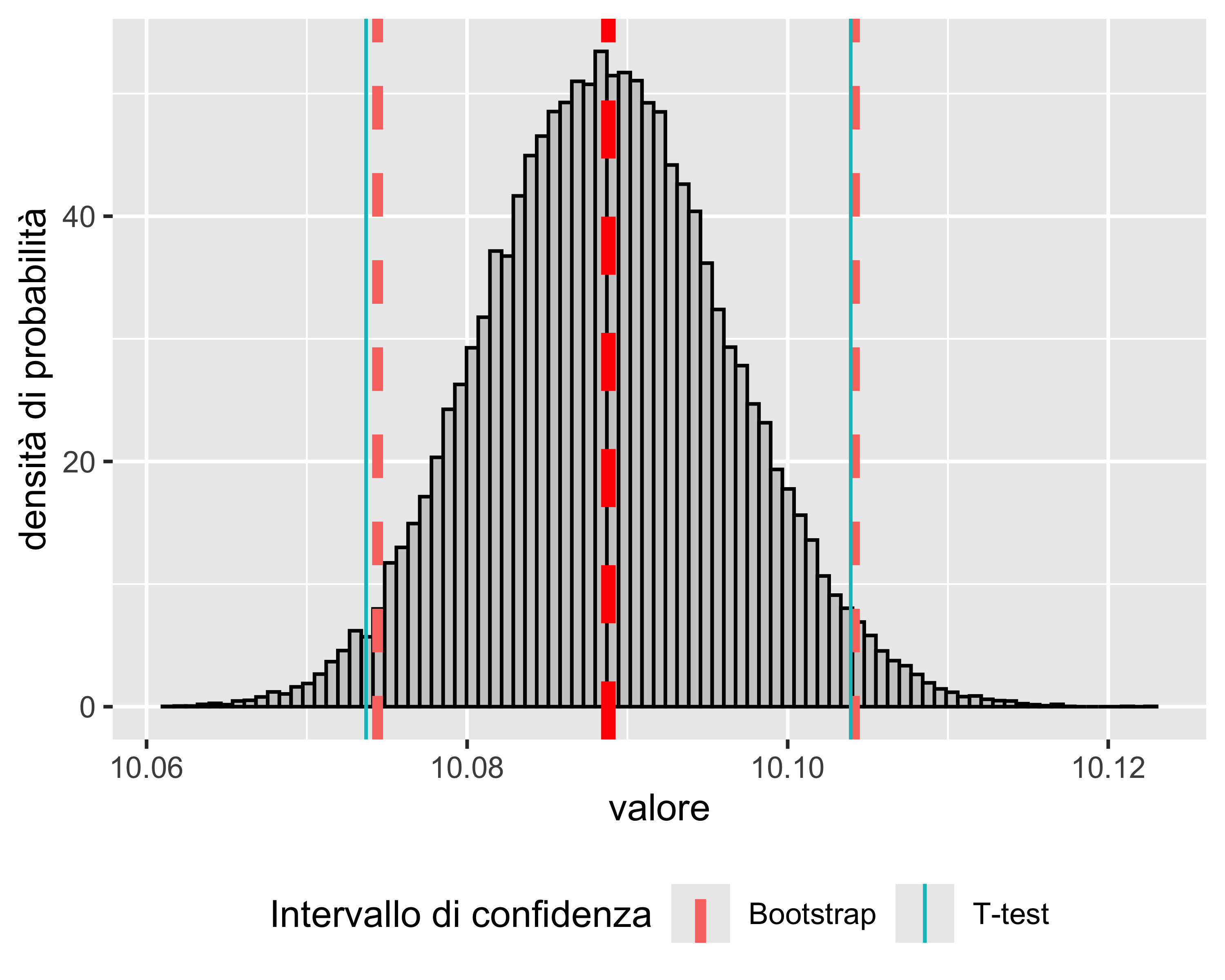
NOTA: confrontando con l’intervallo calcolato dal T-test si nota che il limite inferiore è diverso: ciò è dovuto all’assimmetria della distribuzione del campione di base
Esempio
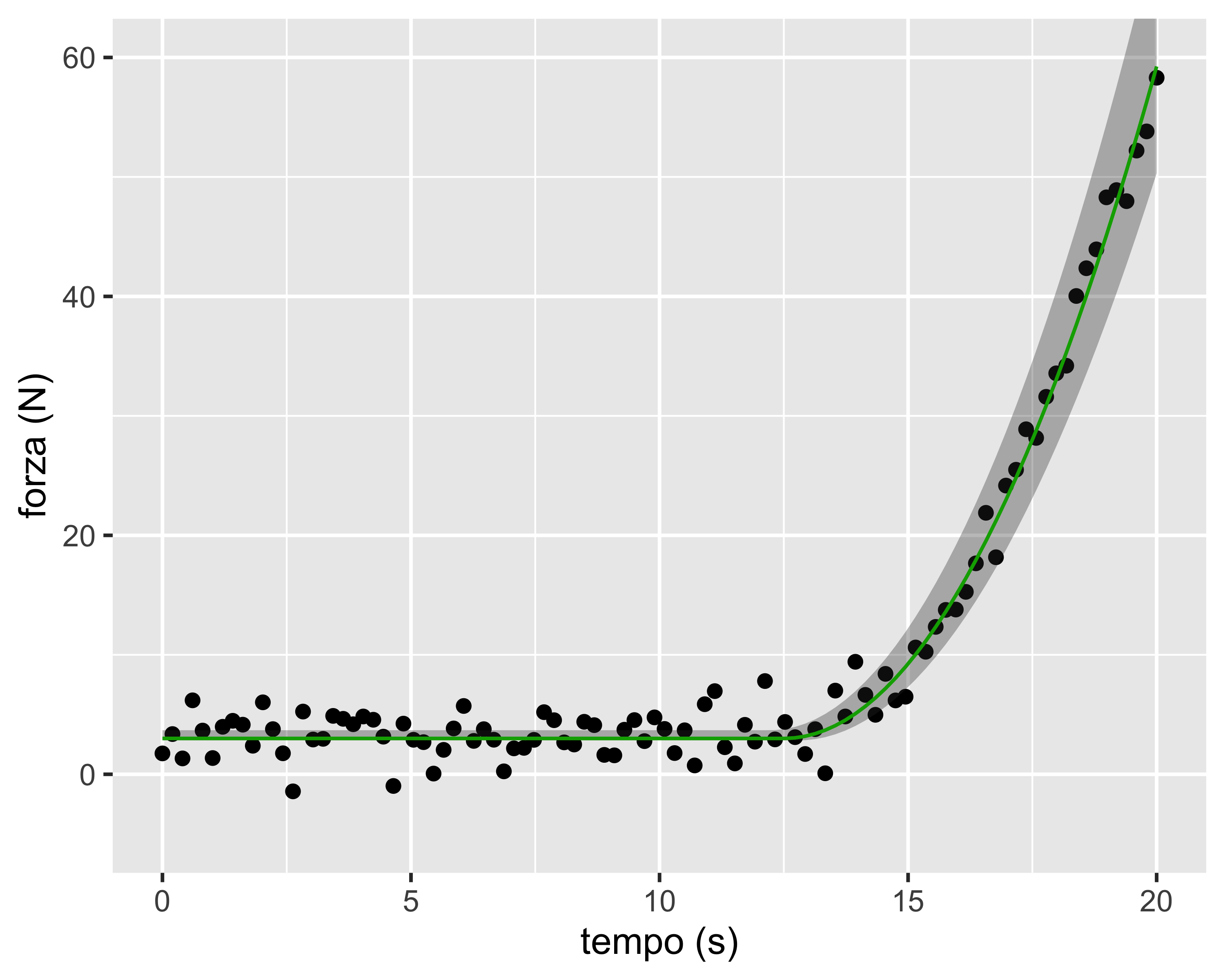
Supponiamo di voler calcolare gli intervalli di confidenza su una statistica calcolata per via numerica: la regressione non-lineare mediante il metodo dei minimi quadrati
Il caso di interesse è la misura dell’istante in cui avviene il contatto tra due corpi, identificato mediante una misura di forza (rumorosa)
Il modello da regredire è: \[ f = \begin{cases} f_0 & t < t_0 \\ a t^2 + b t + c & t \geq t_0 \end{cases} \]
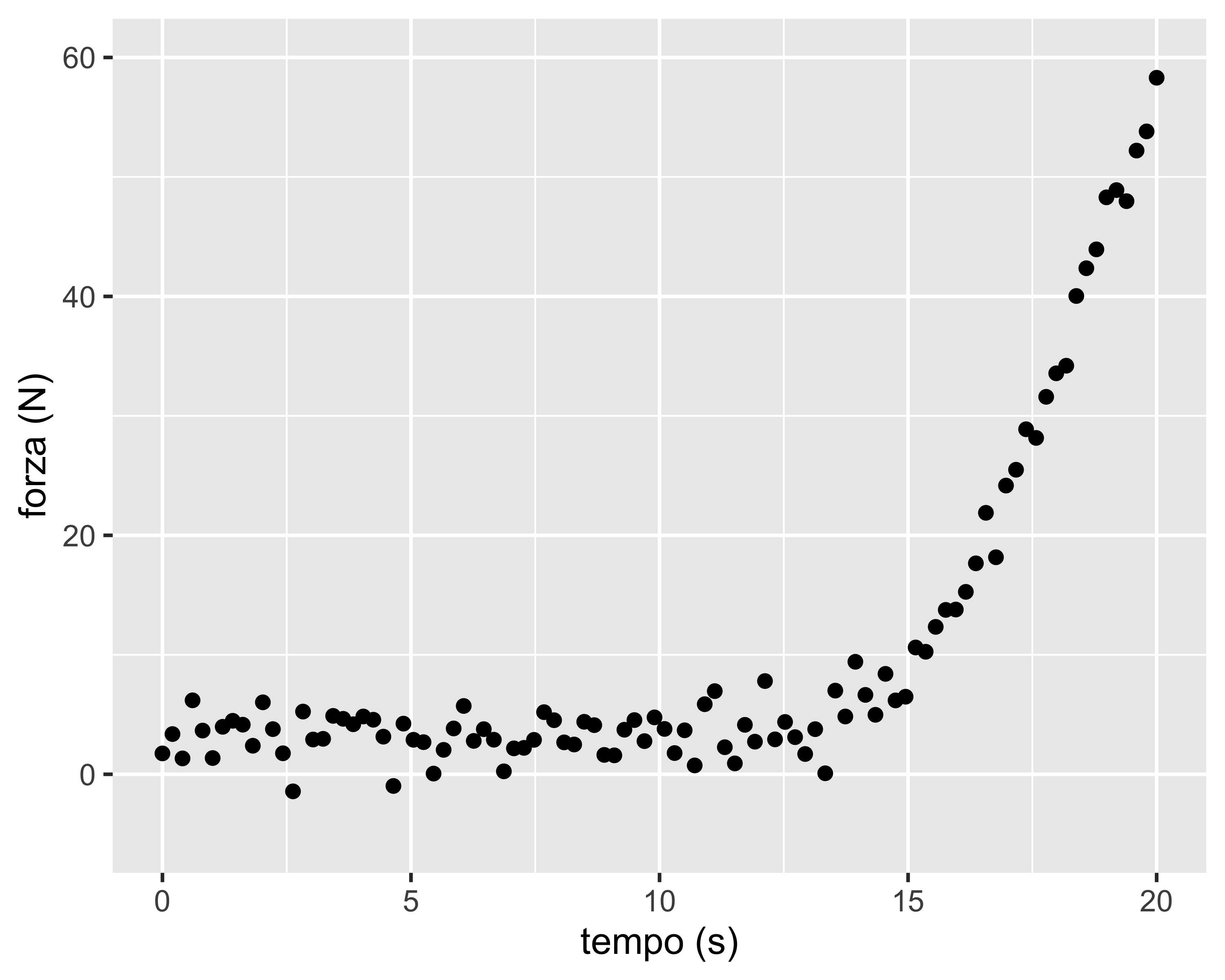
Dove \(f\) è la forza, \(f_0\) è il livello della forza prima del contatto, \(t_0\) è l’istante del contatto, e \(b, ~c\) parametri di forma della curva di contatto
Esempio
Siccome \(f(\cdot)\) deve essere continua con derivata continua, risulta \(2at_0+b=0\) e \(at_0^2+bt_0+c=f_0\) e quindi si hanno tre parametri: \[ f = \begin{cases} f_0 & t < t_0 \\ a t^2 - (2at_0)t + at_0^2+f_0 & t \geq t_0 \end{cases} \] Mediante regressione ai minimi quadrati e successivo bootstrap è possibile identificare l’istante di contatto e il relativo intervallo di confidenza per un assegnato livello di confidenza (in questo caso 95%)
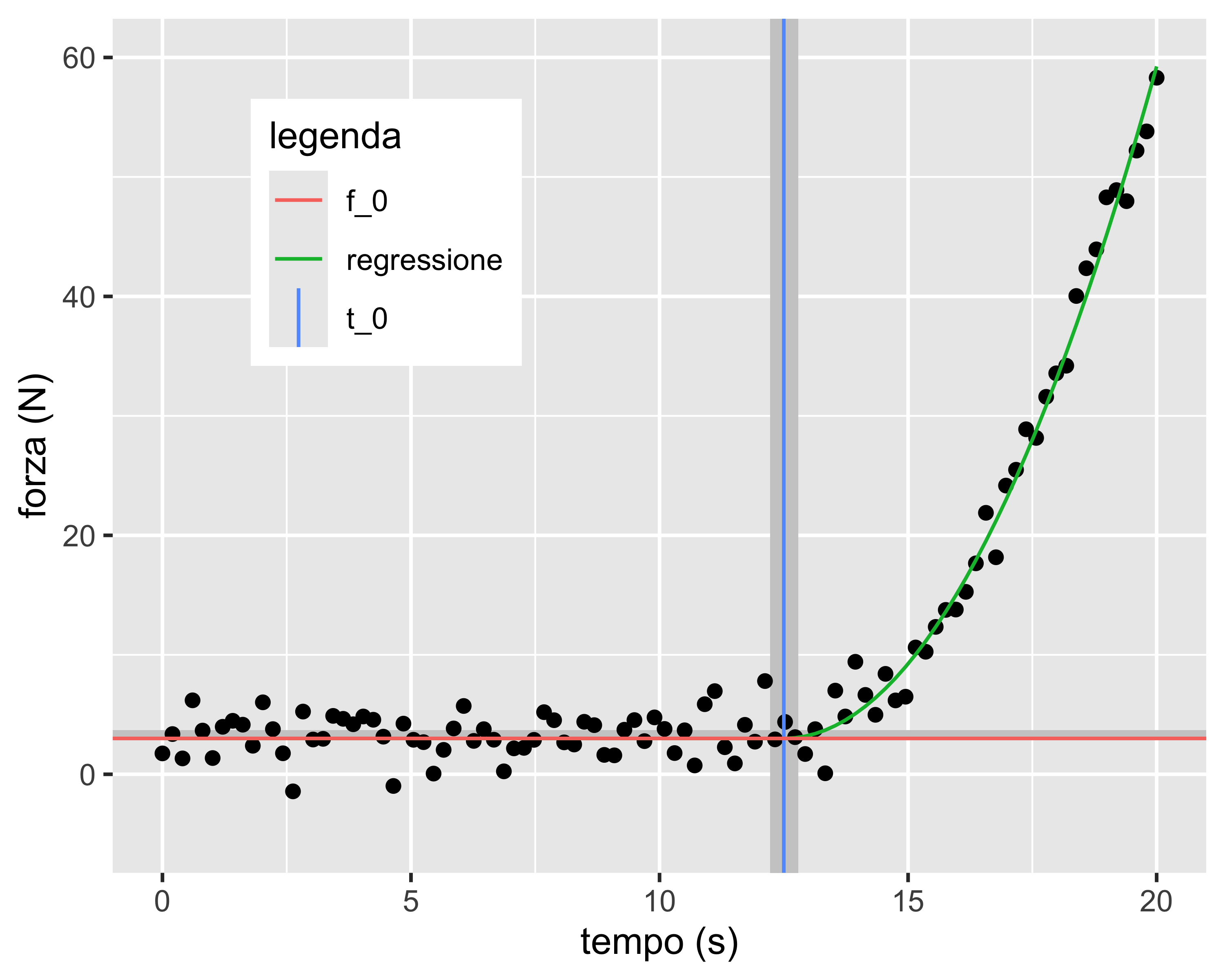
Esempio
È anche possibile calcolare, per ogni valore del predittore \(t\), gli estremi di \(f\) considerando tutte le possibili combinazioni dei tre parametri \(f_0,~t_0,~a\)
In questo modo è possibile identificare una banda di confidenza sulla funzione interpolante (per un assegnato livello di confidenza)