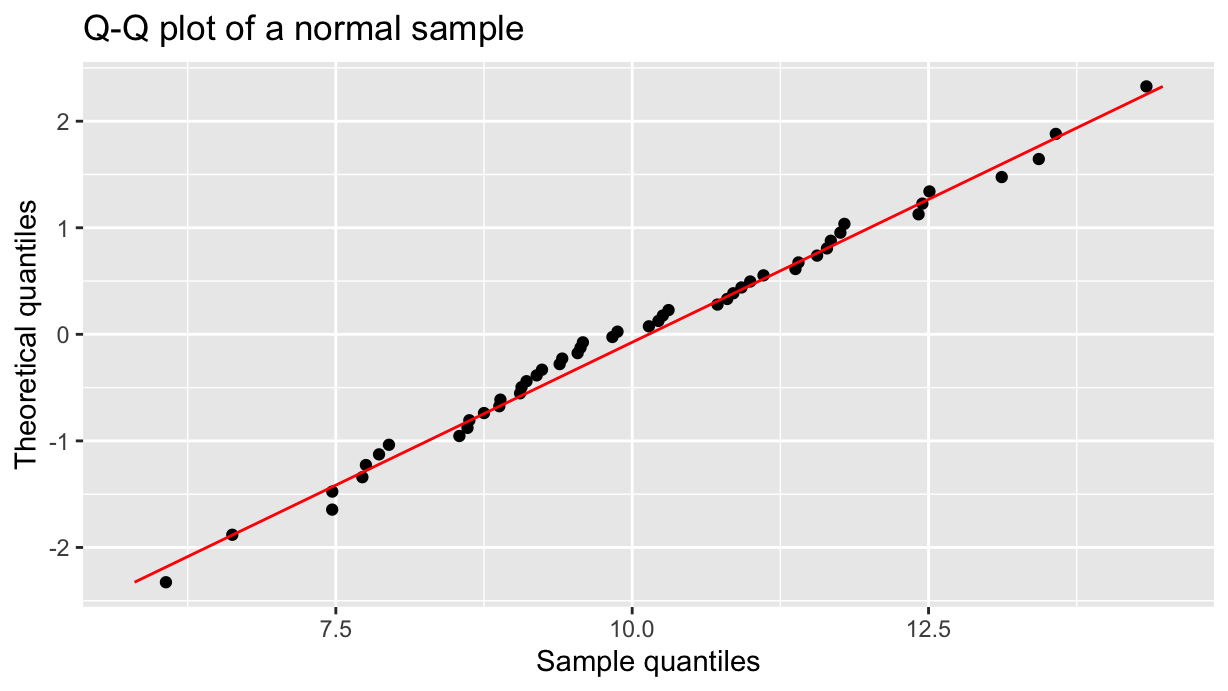
One of the most common graphical techniques for checking the normality of a sample is the quantile-quantile (or Q-Q) plot. It plots a scatter of the sample quantiles versus the expected, or theoretical, quantiles on the normal distribution, plus a diagonal line passing through the first and third quantiles. The more the points are aligned with the diagonal line, the more the sample is likely to be normally distributed. For example:
set.seed(123)data <-tibble(i =1:50,x =rnorm(length(i), mean=10, sd=2))data %>%ggplot(aes(sample = x)) +stat_qq() +stat_qq_line(color="red") +labs(title ="Q-Q plot of a normal sample", x="Theoretical quantiles", y="Sample quantiles") +coord_flip()
Note that I have flipped the coordinates, for a simpler comparison with the normal probability plot that we are going to build later on.
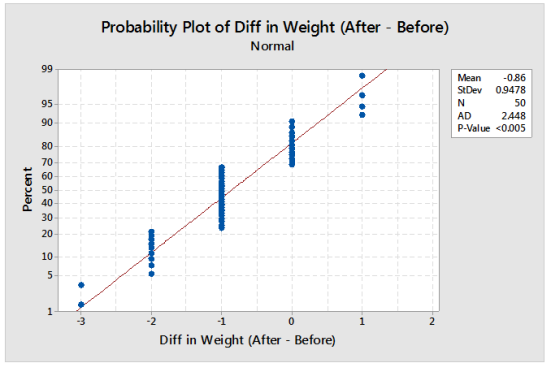
Some other statistical software, like Minitab, provide an analogous plot for the same purpose, called normality plot, where the sample values are on the abscissa and the ordinate axis reports the empirical cumulative distribution function (ECDF) of the sample, scaled according to the normal distribution, so that the resulting scatter is straight for a normal sample.
Minitab normal probability plot
Let’s see one step at a time:
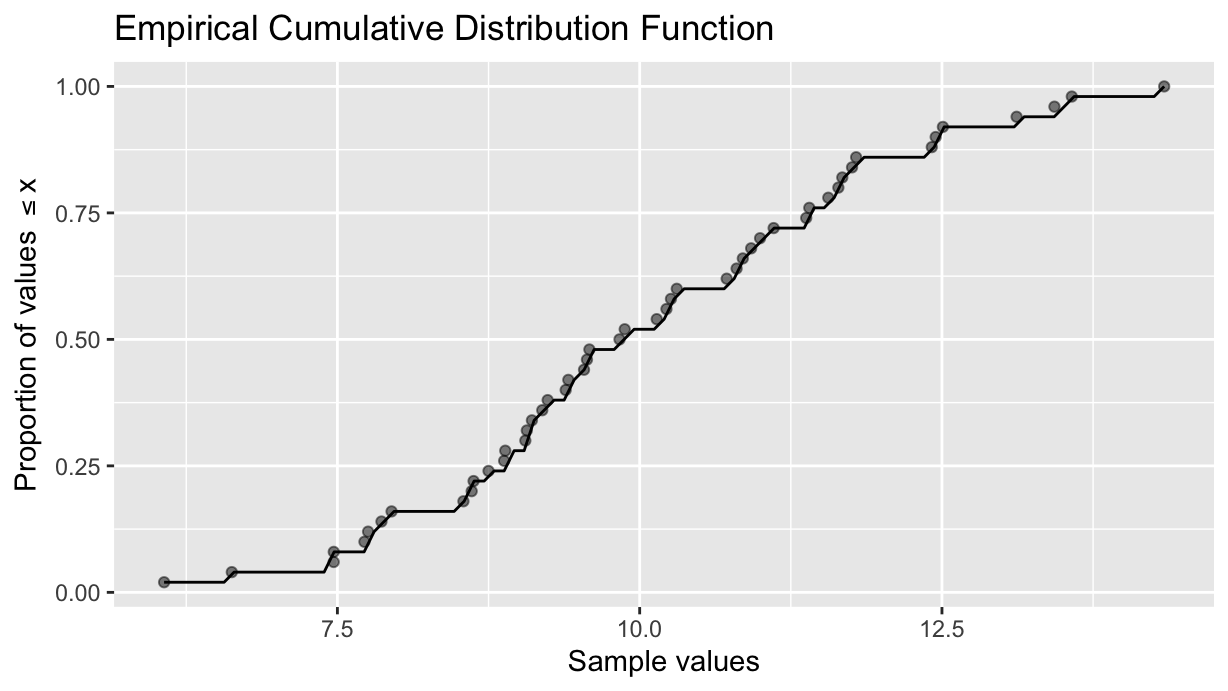
The ECDF
R provides the ecdf() function. It is a factory function that generates the function that given a sample value returns the proportion of values in the sample that are less than or equal to the given value. For example:
data.ecdf <-ecdf(data$x)data %>%ggplot(aes(x=x, y=data.ecdf(x))) +geom_point(alpha=0.5) +geom_function(fun=data.ecdf, xlim=range(data$x)) +labs(title="Empirical Cumulative Distribution Function", x="Sample values",y=TeX("Proportion of values $\\leq x$"))
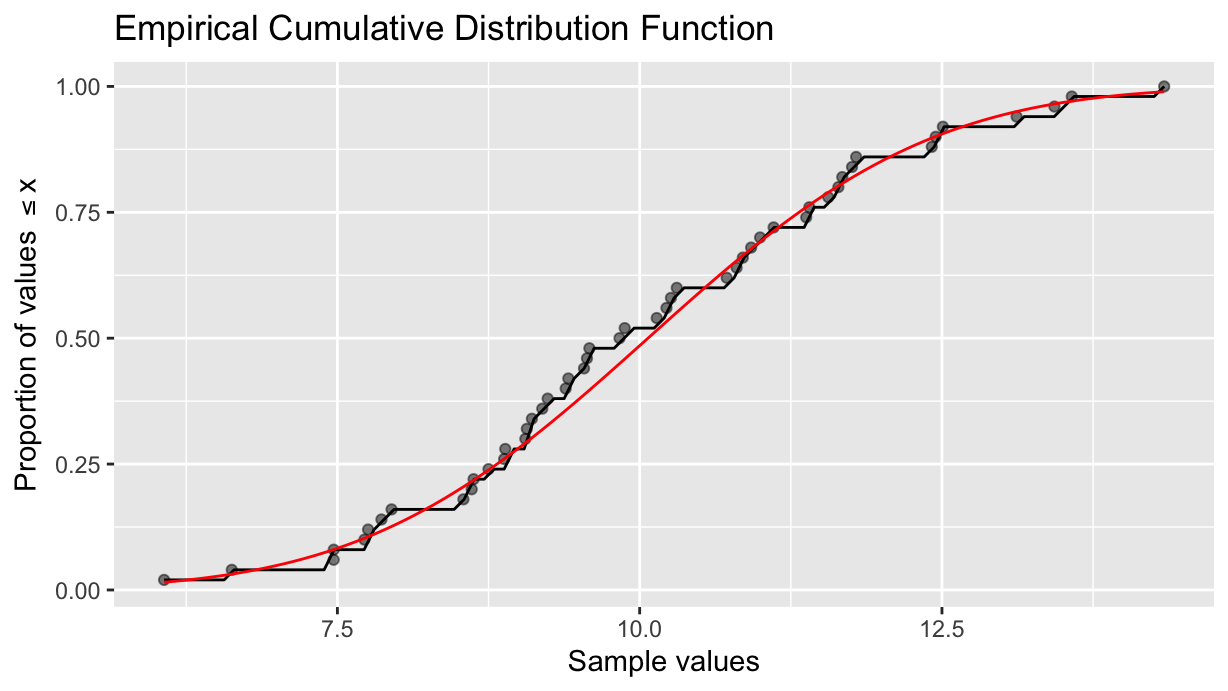
Comparing to the normality
The ECDF can be compared to the expected normal distribution by adding the normal CDF function, here plotted in red:
Now, the normal probability plot is essentially the same plot as the last one, but with the y-axis scaled according to the normal distribution, so that the resulting scatter and curves appear straight.
In ggplot, we can use the scales package to achieve this, through the scale_y_continuous() function. The diagonal line, in this case, is simply the CDF function of the normal distribution with the same mean and standard deviation of the sample.
We can build a general function like this:
normplot <-function(data, var, breaks=seq(0.1, 0.9, 0.1), linecolor="red") { m <- data %>%pull({{var}}) %>%mean() s <- data %>%pull({{var}}) %>%sd() data %>%mutate(ecdf =ecdf({{var}})({{var}})) %>%arrange({{var}}) %>%ggplot(aes(x={{var}}, y=ecdf), data=.) +geom_point() +geom_function(fun = pnorm, args=list(mean=m, sd=s), color=linecolor) +scale_y_continuous(trans=scales::probability_trans("norm"), breaks=breaks) +labs(y="Normal probability")}
Note the use of the {{var}} syntax, which is a feature of the rlang package that allows us to pass the name of the variable as an argument to the function, to be then expanded as a symbol in the dplyr functions.
Let’s see how it works:
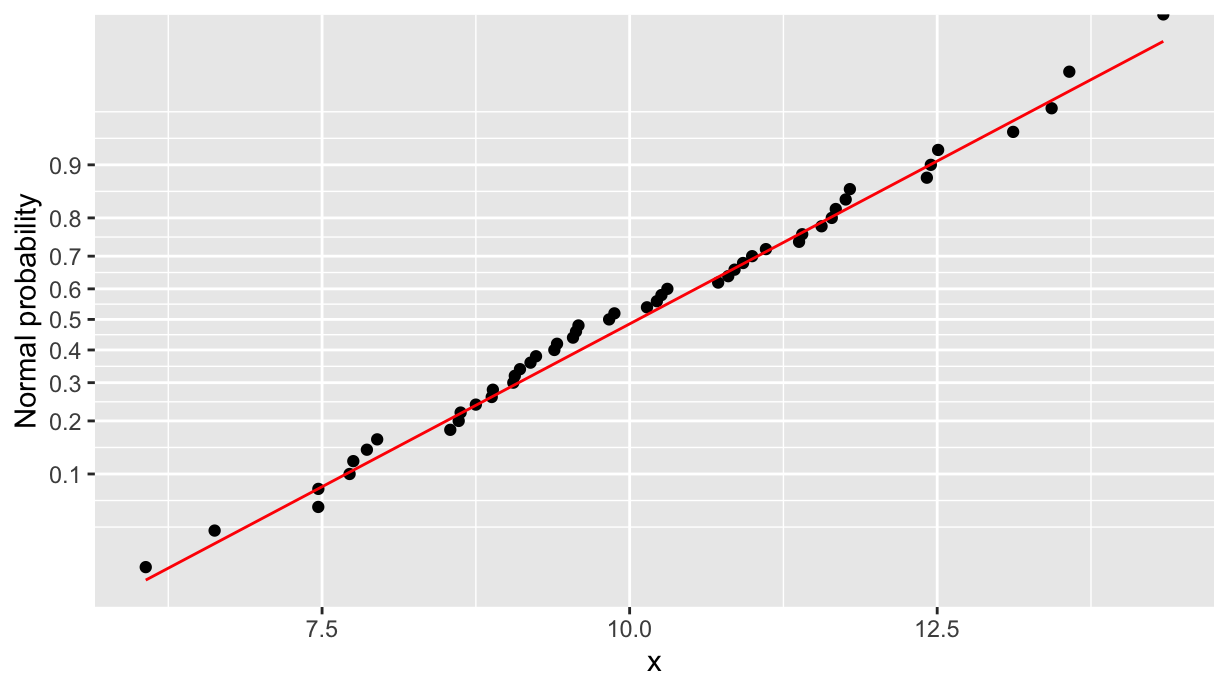
normplot(data, x)
Compare it with the Q-Q plot above, paying attention that the two axes are flipped. The only difference is that the diagonal line is now the CDF function rather than a line passing through the first and third quartiles.
Using the Q-Q plot or the normal probability plot is just a matter of personal preference: the former provides theoretical quantiles, the latter the theoretical probabilities.