Regressione
Analisi Dati e Statistica, 2025–26
![]()
Ultimo aggiornamento: 17/06/2026
Coefficiente di Determinazione
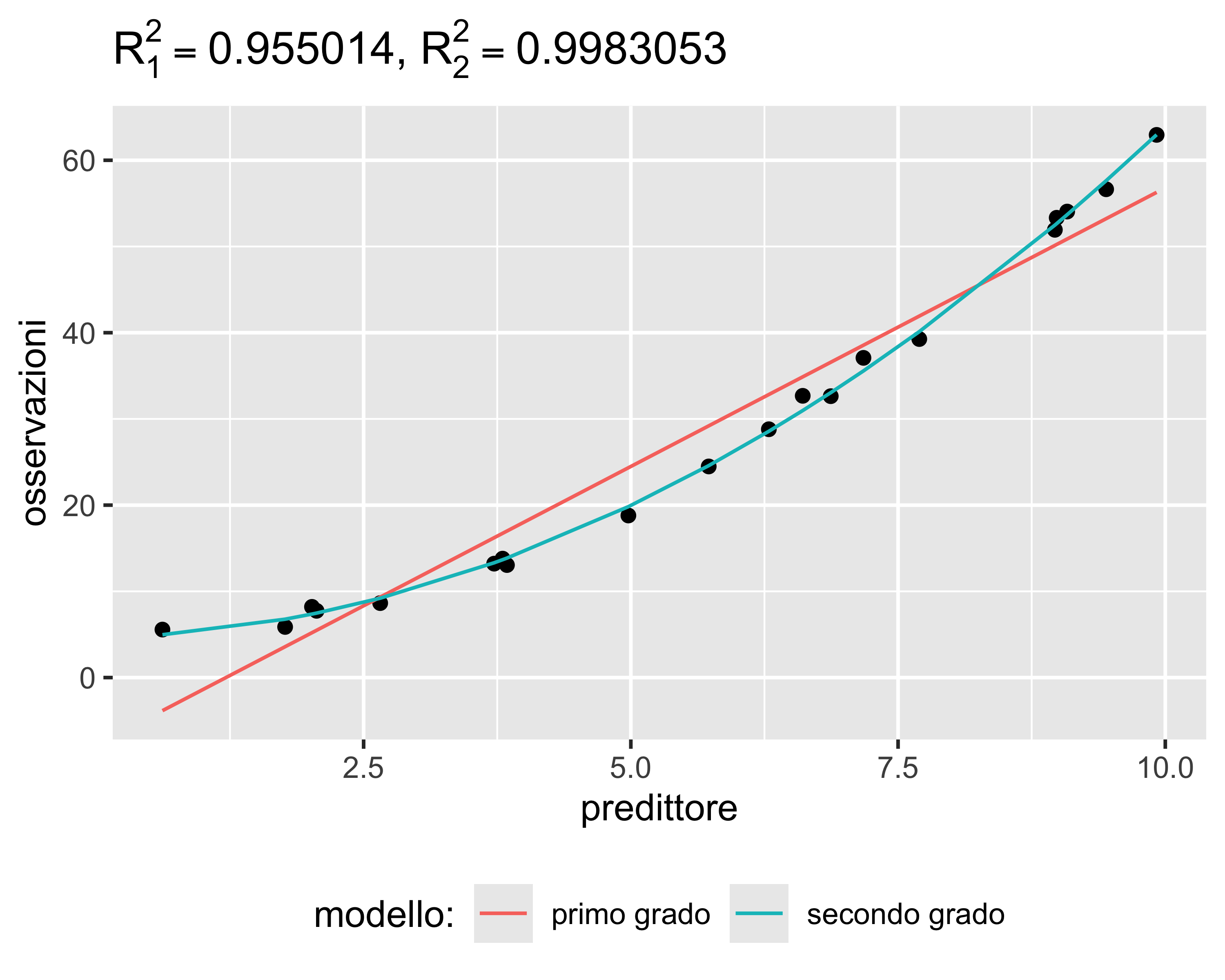
Il coefficiente di merito più utilizzato per valutare una regressione è il coefficiente di determinazione \(R^2\)
È definito come \(R^2 = 1 - \frac{SS_\mathrm{res}}{SS_\mathrm{tot}}\), dove \(SS_\mathrm{res} = \sum \varepsilon_i^2\) e \(SS_\mathrm{tot} = \sum(y_i - \bar y)^2\)
Se i valori regrediti corrispondono ai valori osservati \(y_i=\hat{y_i}\), allora i residui sono tutti nulli e vale \(R^2 = 1\)
La qualità della regressione diminuisce al diminuire di \(R^2\)

Sotto-adattamento
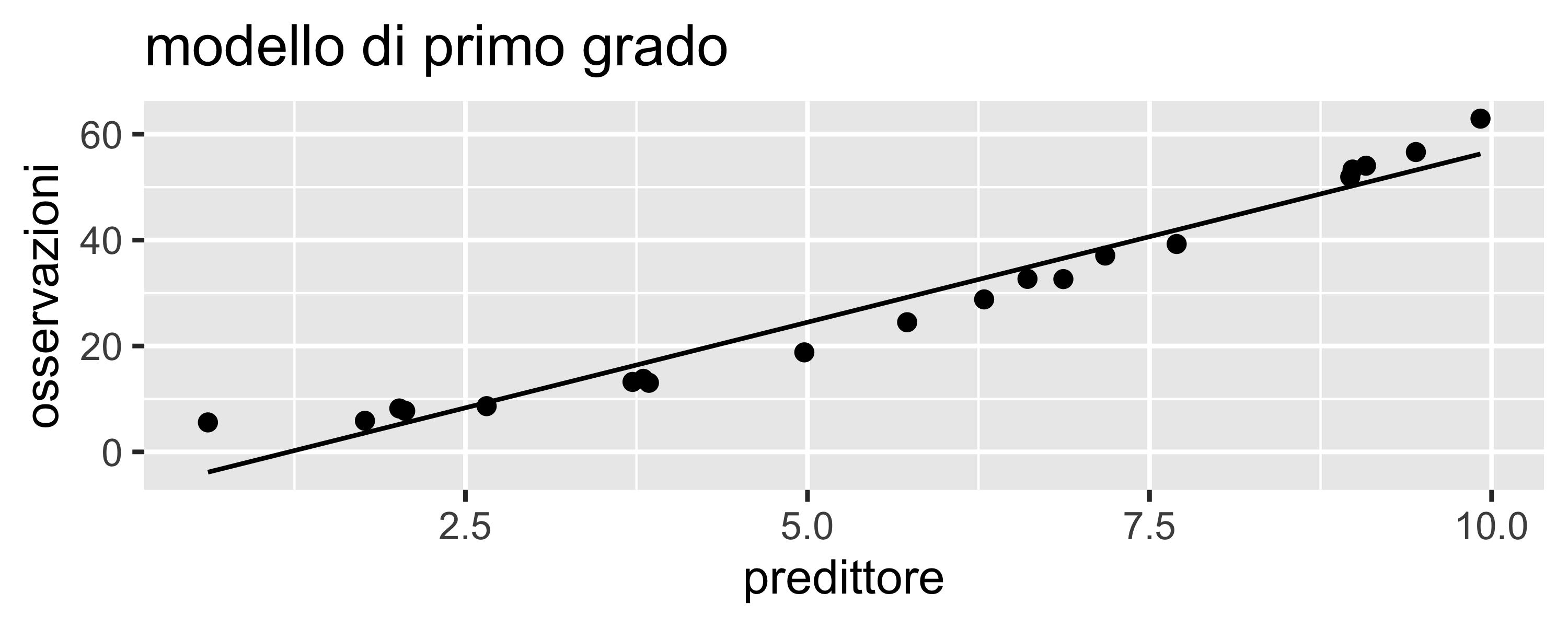
Si ha sotto-adattamento (o under-fitting) quando il modello ha un grado inferiore all’apparente comportamento delle osservazioni
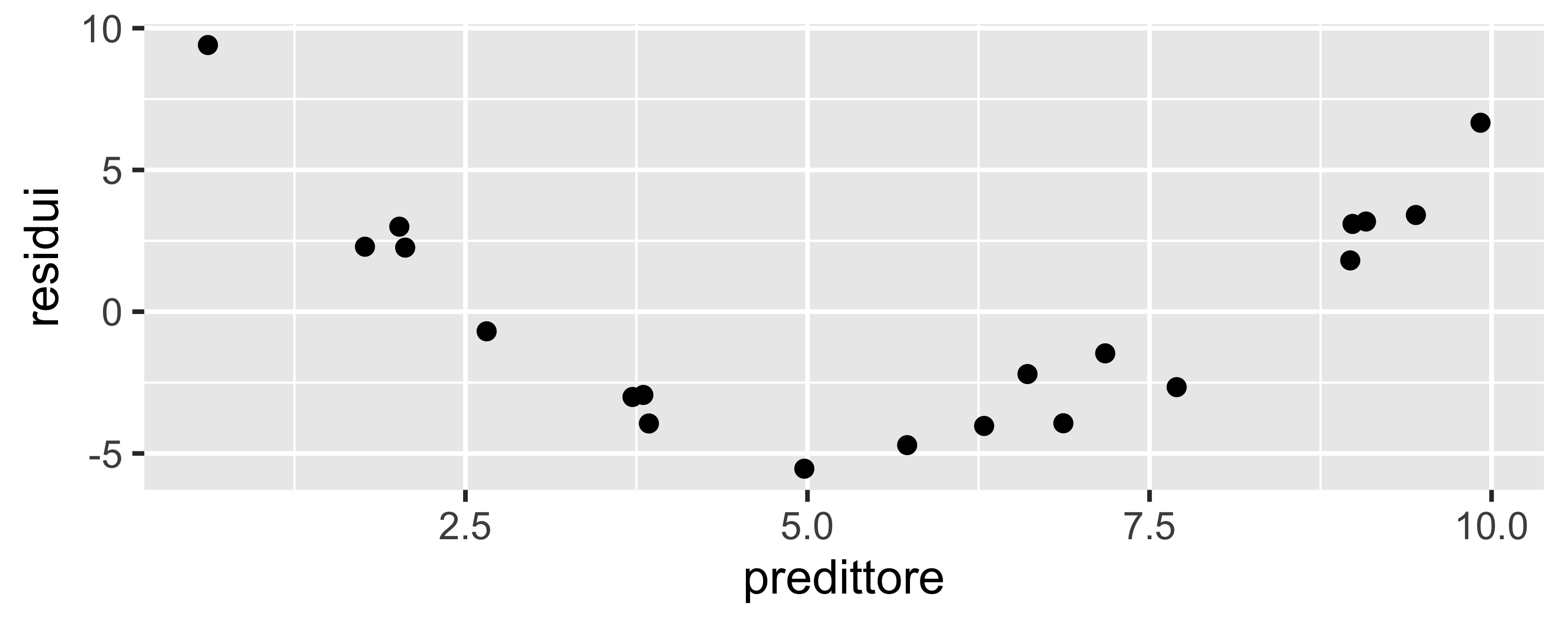
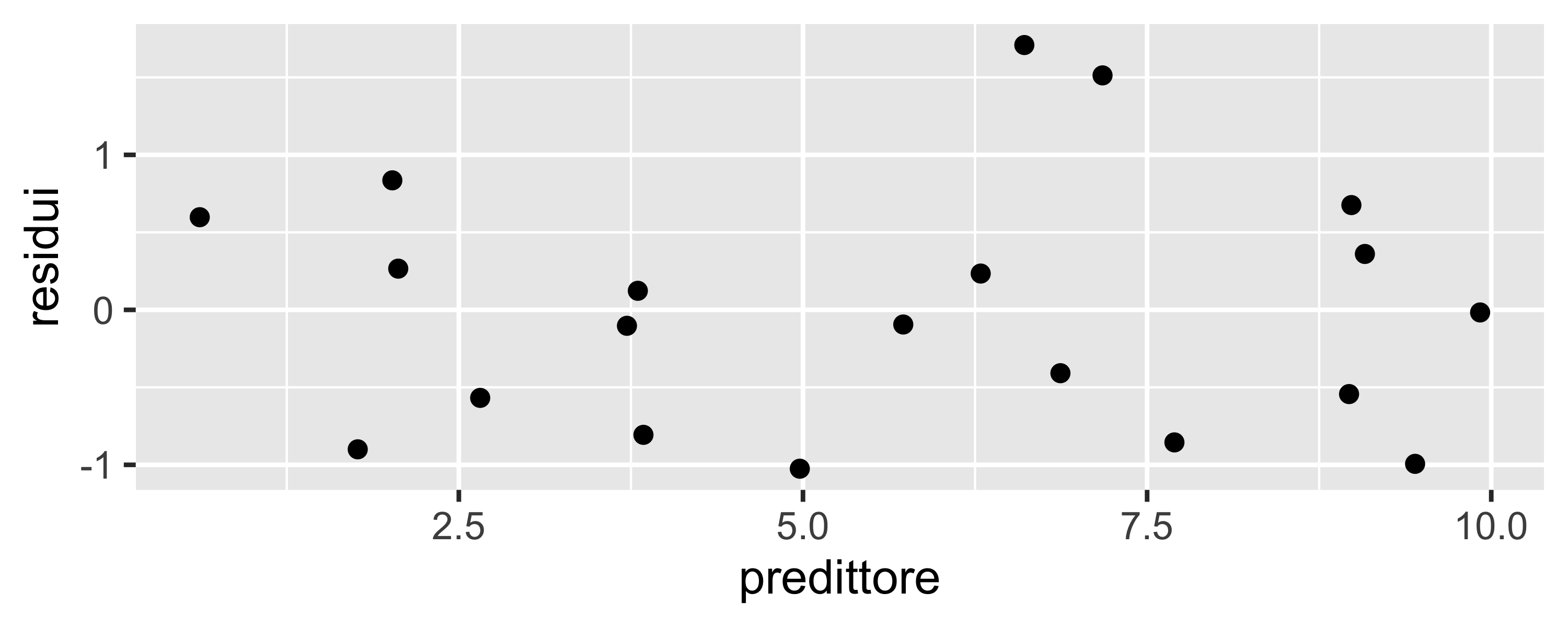
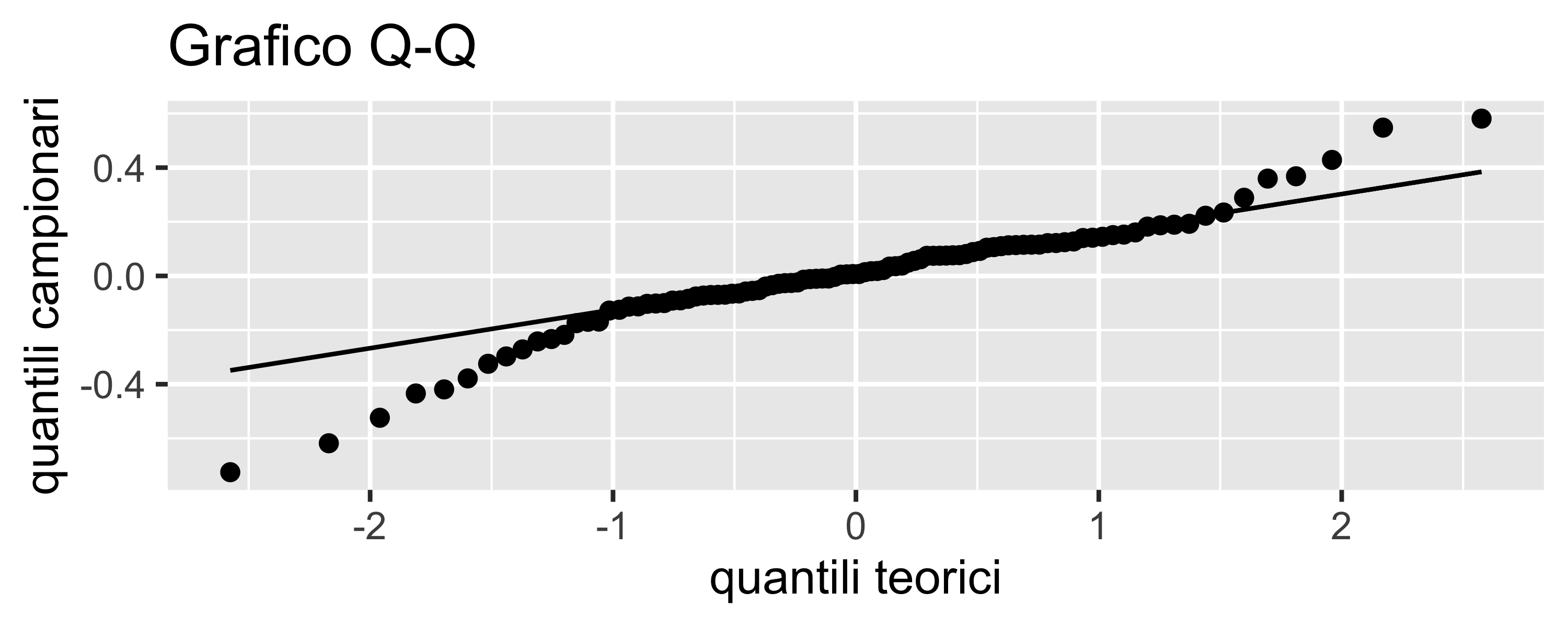
Può essere evidenziato, oltre che da un \(R^2\) basso, studiando la distribuzione dei residui: se c’è sotto-adattamento i residui possono essere non-normali e, soprattutto, mostrare degli andamenti, o pattern
Un pattern è un andamento regolare dei residui in funzione dei regressori
Dal numero di massimi e minimi presenti nell’eventuale pattern è possibile stimare quanti gradi mancano
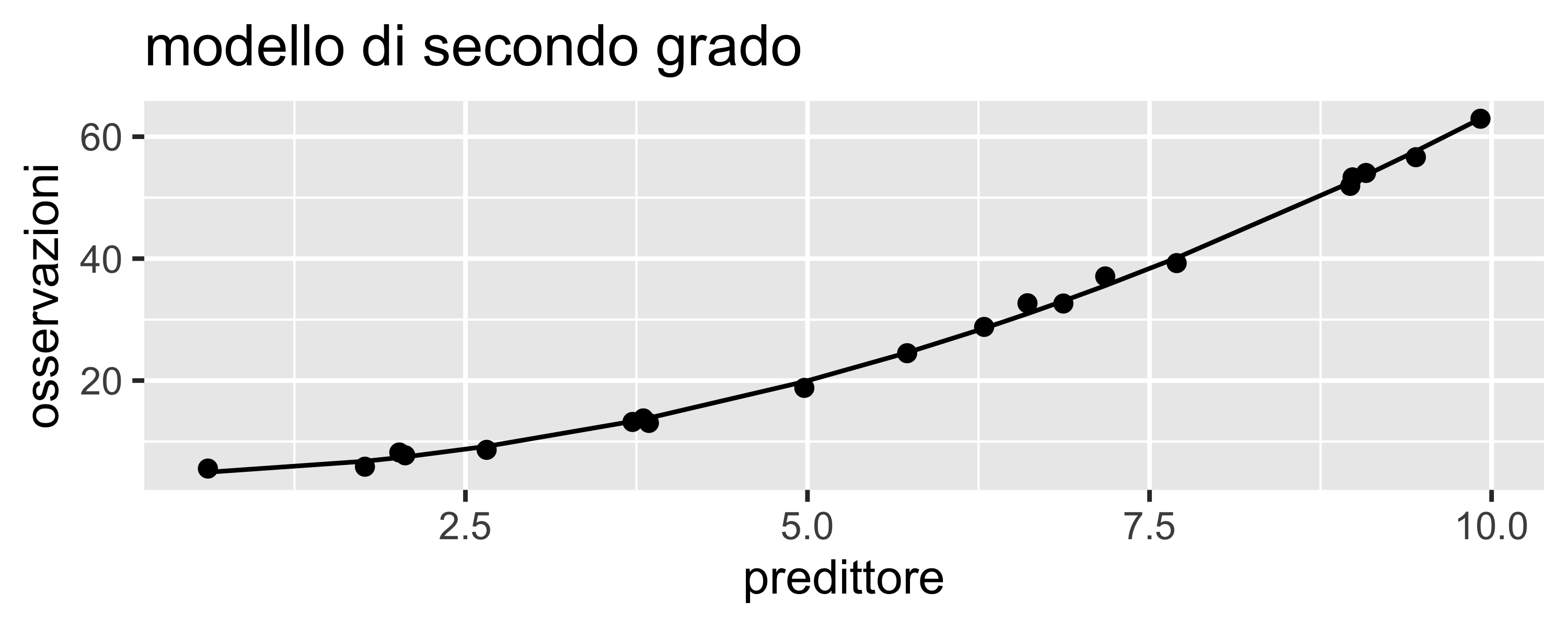
Sovra-adattamento
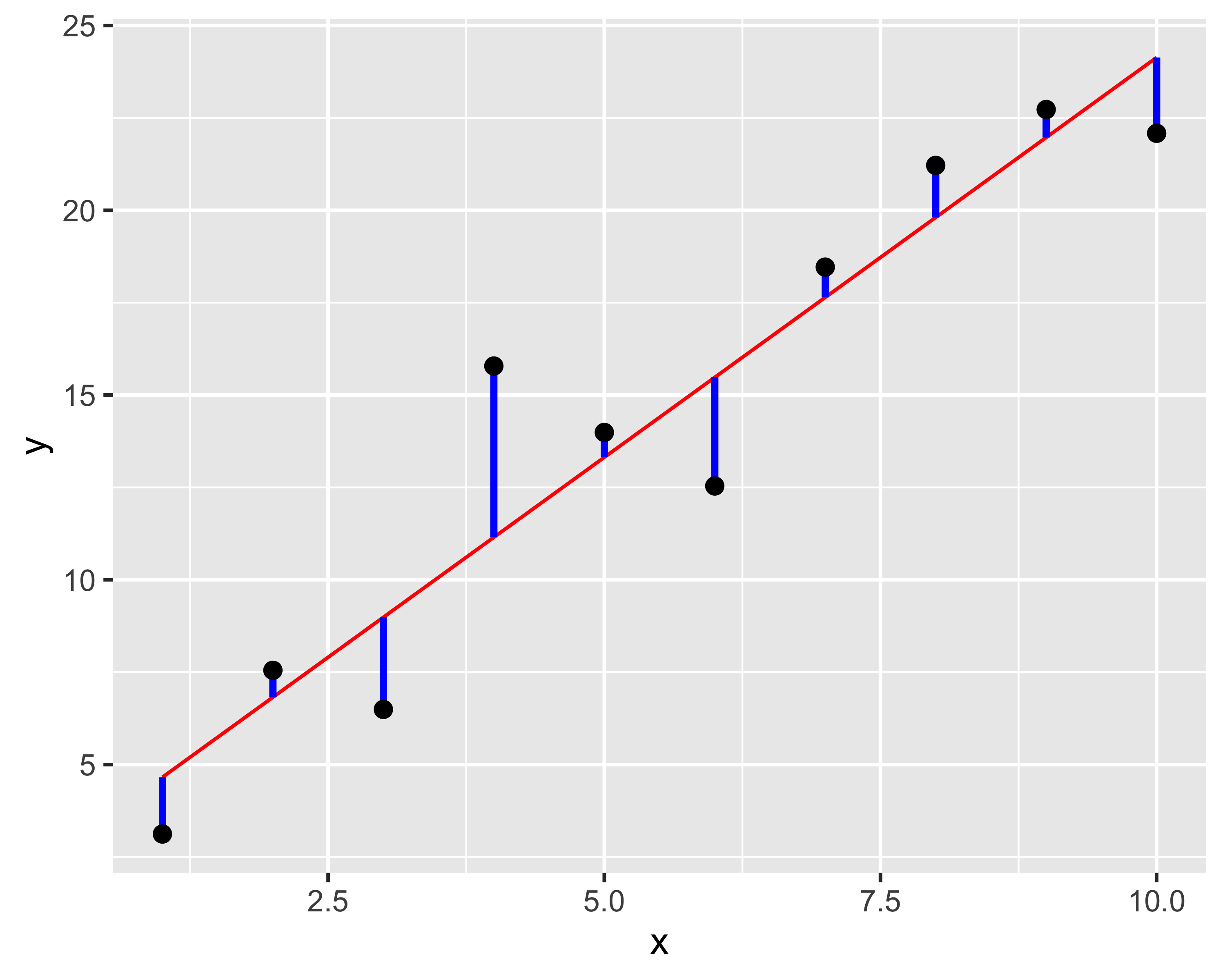
Se il grado del modello è eccessivo, il modello tende a inseguire i singoli punti
Il valore di \(R^2\) cresce, raggiungendo 1 quando il grado è uguale al numero di osservazioni meno 1
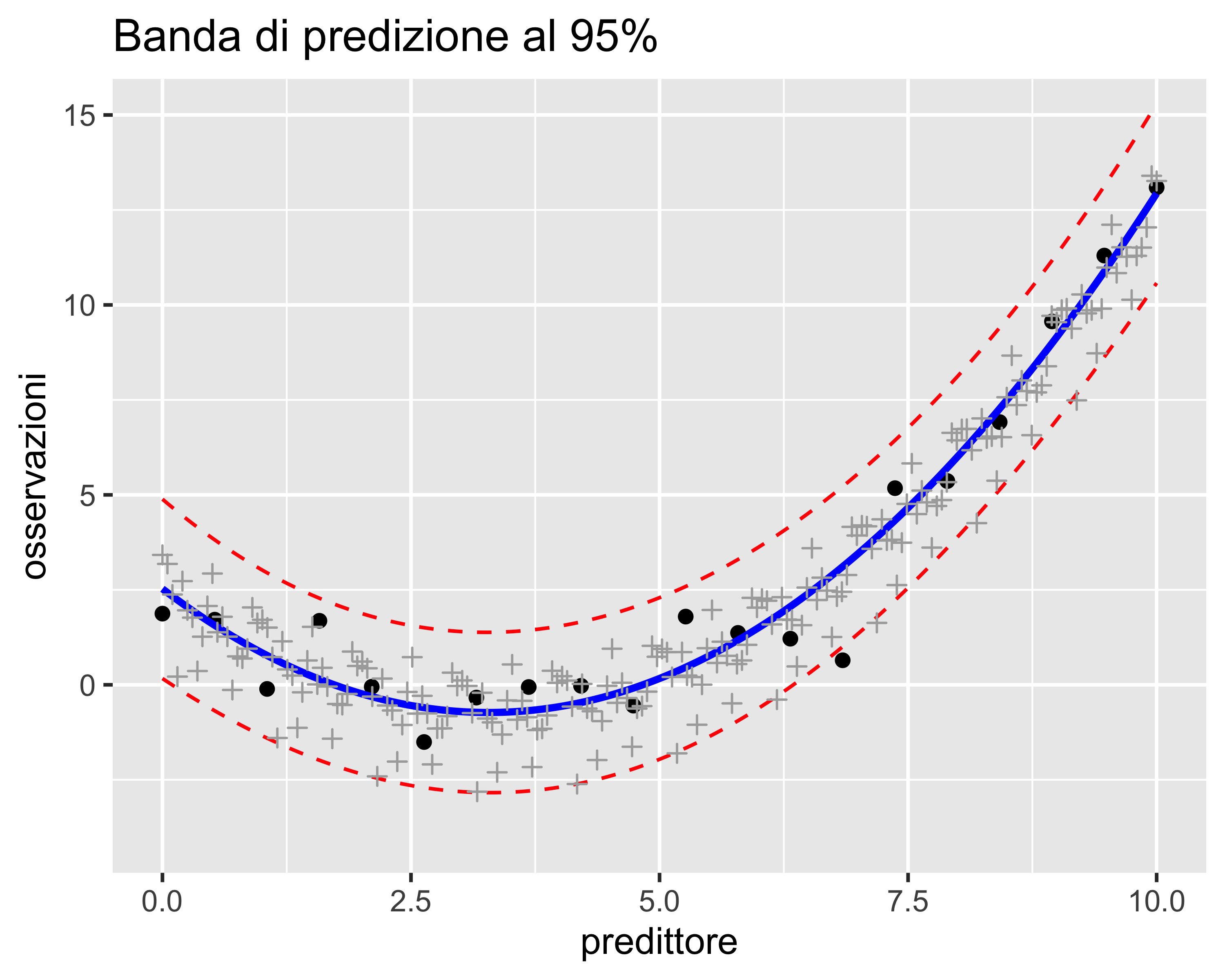
Tuttavia il modello perde di generalità e non riesce più a predirre correttamente nuovi valori acquisiti in un secondo momento (le crocette rosse in figura)
Il sovra-adattamento ha effetti particolarmente drammatici in caso di estrapolazione, cioè quando si valuta il modello al di fuori dell’intervallo in cui è stato regredito

Bande di Predizione
È una banda simmetrica rispetto alla regressione all’interno della quale le osservazioni (presenti e future) hanno una probabilità assegnata di ricadere
In generale, per un numero di osservazioni sufficientemente grande (\(>50\)) la banda di predizione al 95% contiene il 95% delle osservazioni
Bande di Confidenza
È una banda simmetrica rispetto alla regressione all’interno della quale il valore atteso del modello ha una probabilità assegnata di ricadere
È sempre più stretta rispetto alla banda di predizione
È l’equivalente multi-dimensionale dell’intervallo di confidenza per un T-test: come questo è l’intervallo all’interno del quale ha una assegnata probabilità di rientrare il valore corrispondente all’ipotesi nulla, qui possiamo assumere che il modello “vero” rientri con una certa probabilità nella banda di confidenza
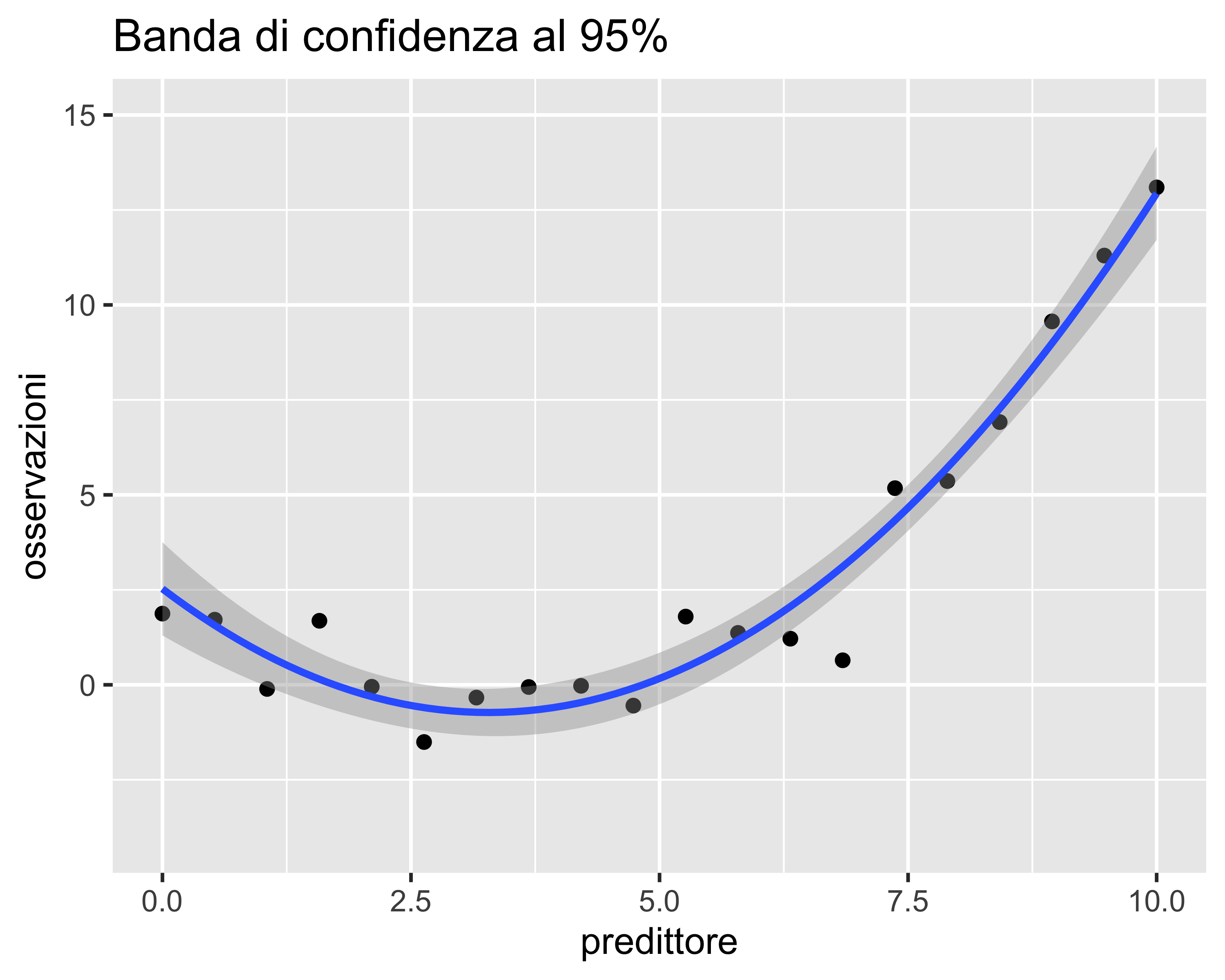
È ottenuto calcolando gli intervalli di confidenza sui parametri della regressione, calcolando poi—per ogni valore del predittore—il valore massimo e minimo della regressione corrispondente ai valori estremi dei parametri nei loro intervalli di confidenza
Basi
La funzione di collegamento (link function) \(g(\cdot)\) è tale per cui:
\[ \begin{align} y_i &= \hat y_i + g(\varepsilon_i) \\ \varepsilon_i &\sim D(p_1,p_2,\dots,p_k);~g(\varepsilon_i)\sim \mathcal{N}(0, \sigma^2) \end{align} \]
Le funzioni di collegamento per le distribuzioni più comuni sono:
| Distribuzione | Funzione di collegamento |
|---|---|
| Normale | \(g(x)=x\) |
| Binomiale | \(g(x)=\mathrm{logit}(x)\) |
| Poisson | \(g(x)=\log(x)\) |
| Gamma | \(g(x)=1/x\) |
In particolare, vale: \(\mathrm{logit}(x)=\frac{1}{1+e^{-p(x-x_0)}}\)
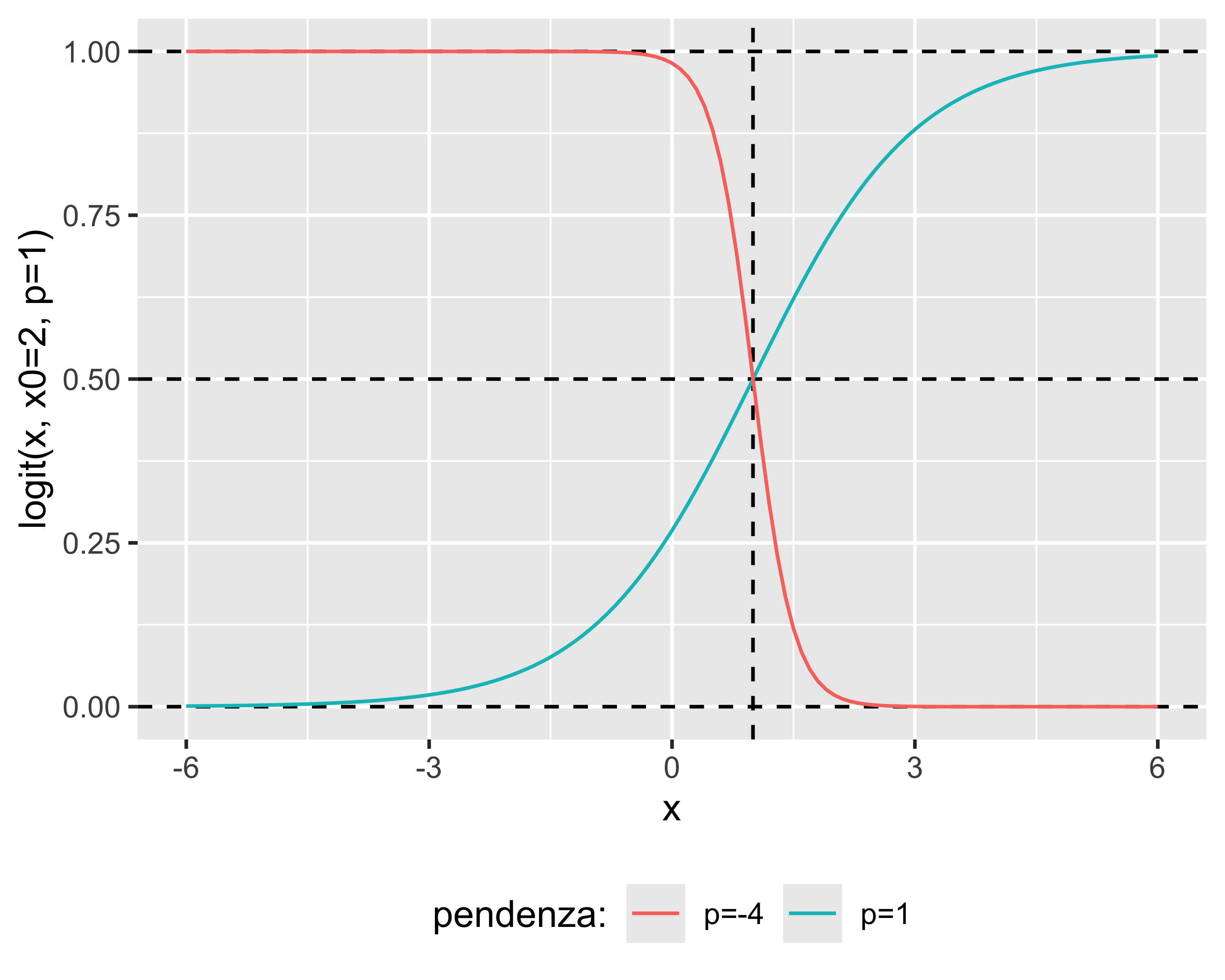
Regressione Logistica
Il caso tipico di regressione logistica è il classificatore di eventi binomiali
consideriamo un processo che, in funzione di uno o più predittori, possa fornire un risultato che può valere solo una di due alternative (successo|fallimento, rotto|integro, vero|falso, 1|0). Vogliamo identificare la soglia dei predittori che commuta il risultato
Una regressione lineare non è adatta alla situazione: è evidente che i residui non sono normali e che la pendenza della regressione dipende molto da quanti punti sono raccolti nelle zone “sicure”
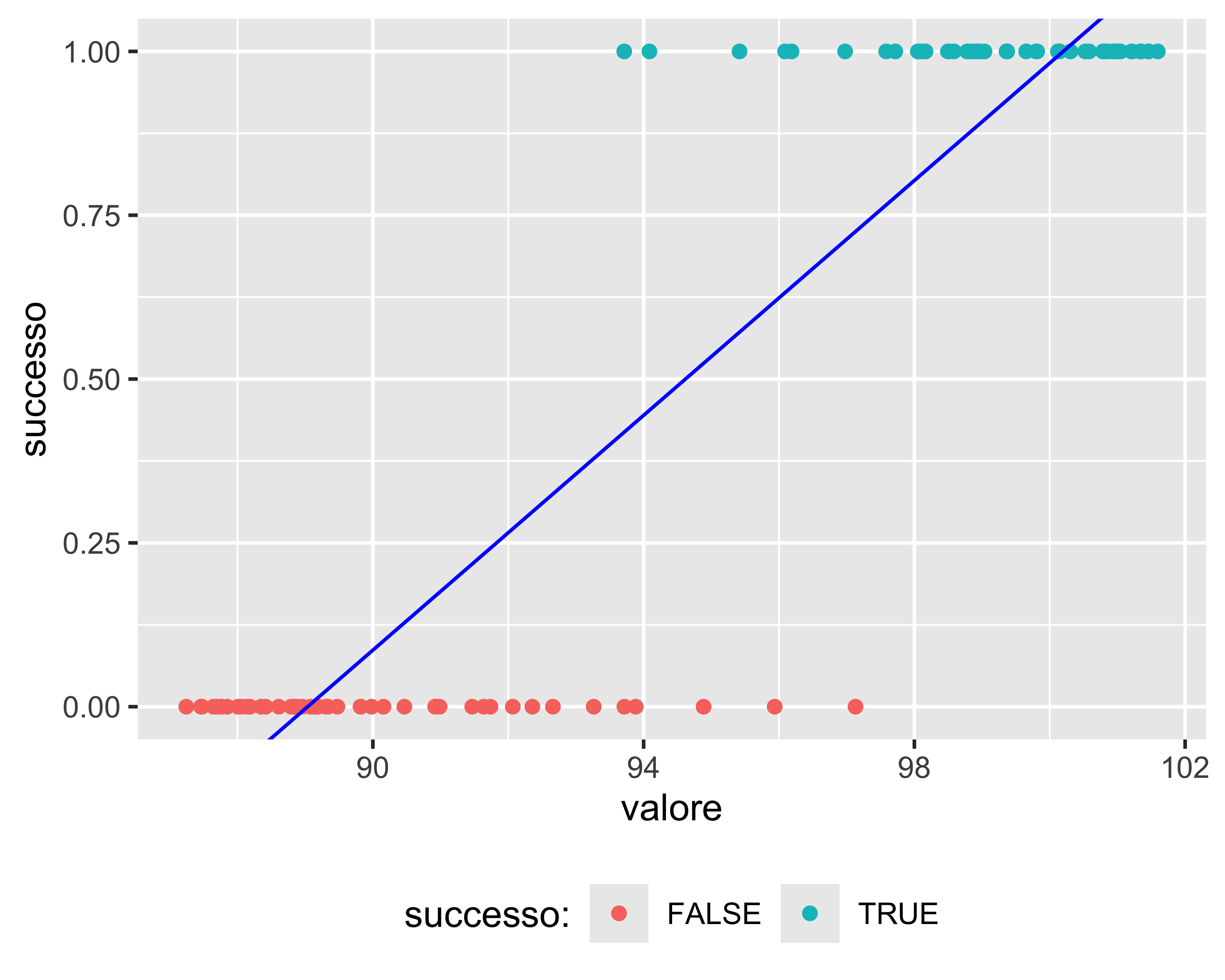
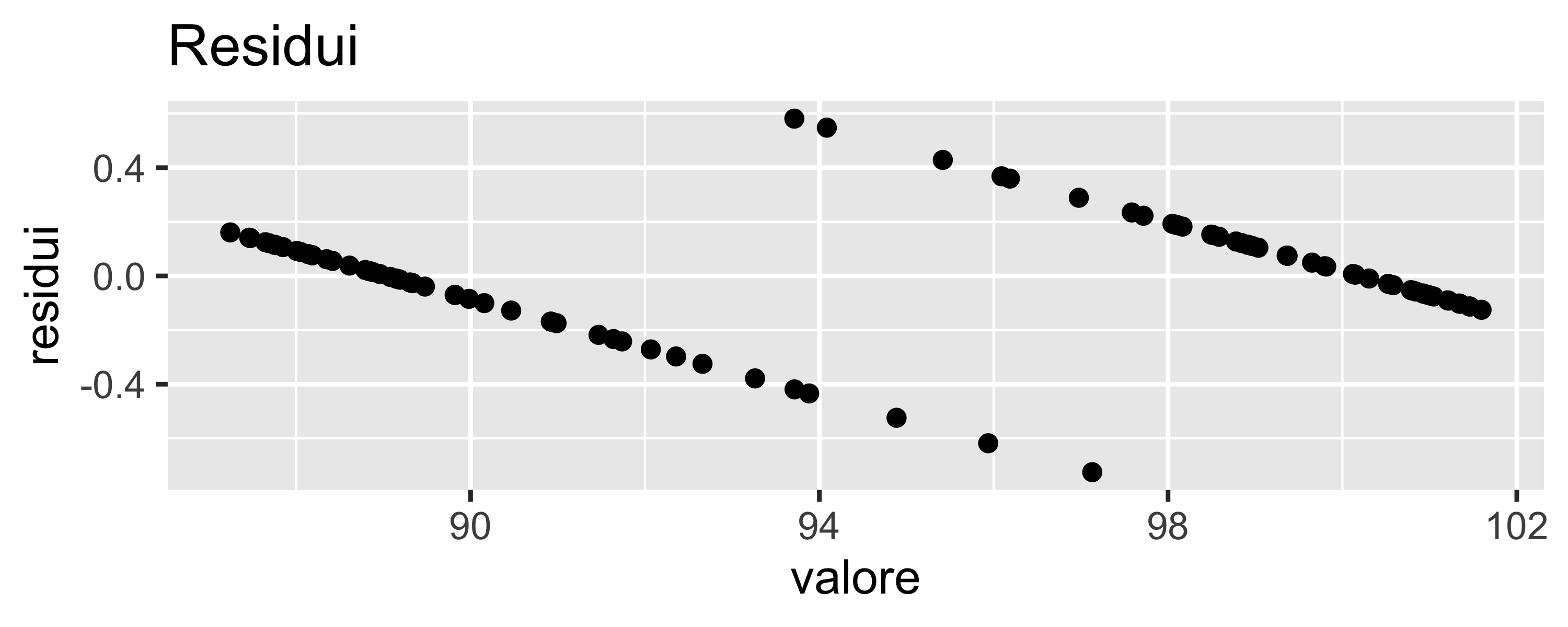
Regressione Logistica
La funzione logistica regredita fornisce il parametro \(x_0\) che identifica il valore che separa una uguale quantità di falsi positivi e falsi negativi
Inoltre, è possibile individuare la soglia opportuna per ottenere una prefissata probabilità di falsi positivi (o falsi negativi)
Questo è il tipo più semplice di machine learning: un classificatore binomiale

Confronto grafico di serie
Supponiamo di avere un processo il cui valore dipende da una variabile \(x\)
Supponiamo che un parametro \(S\) di processo possa influire sul valore in uscita. Ad esempio:
- il valore è la durezza di un metallo, \(x\) è la temperatura, il parametro \(S\) è la quantità di un elemento in lega
- il valore è la produttività di un impianto, \(x\) è un parametro quantitativo di processo, il parametro \(S\) è il tipo di macchina utilizzato

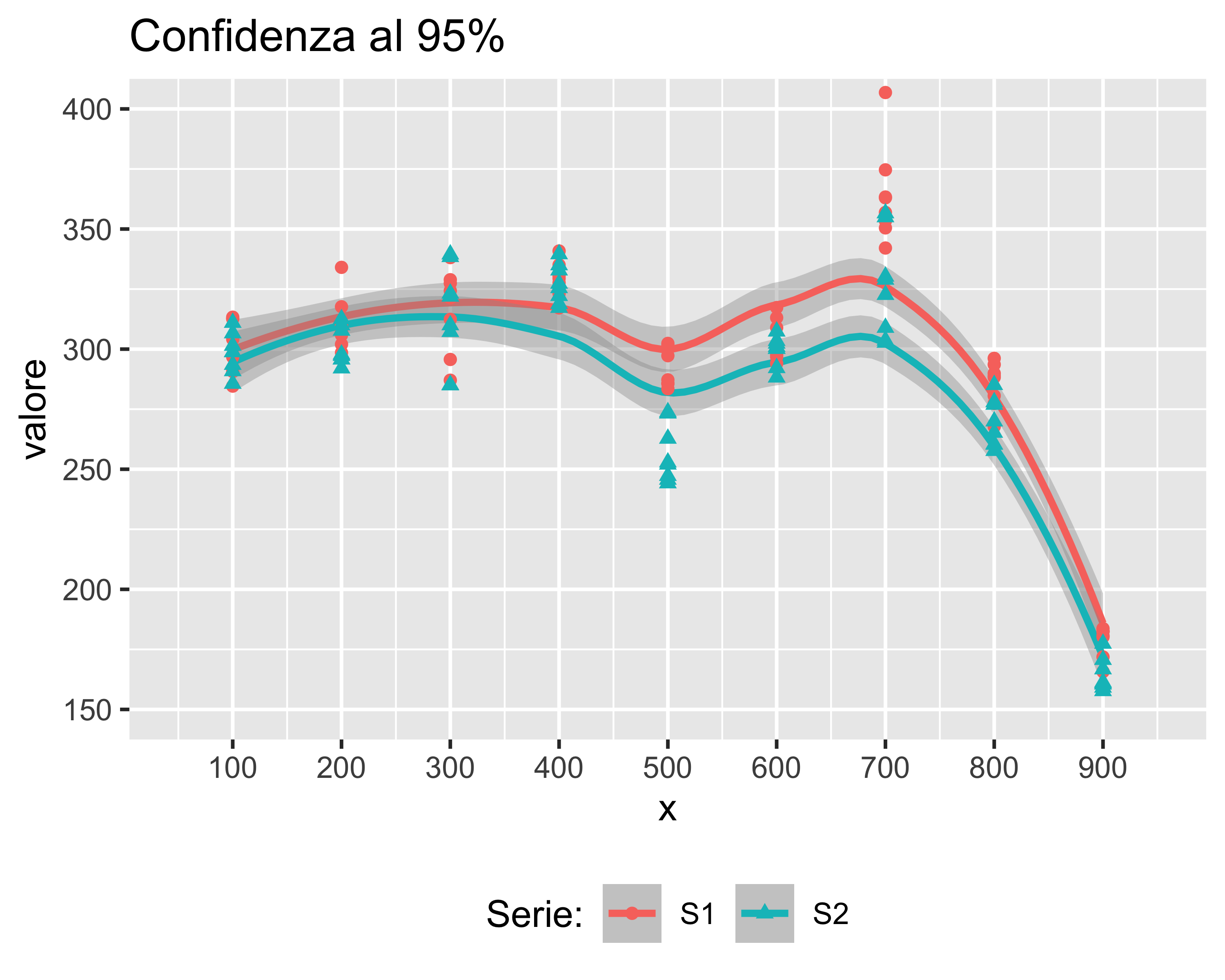
Supponiamo di ripetere 8 volte una misurazione del valore in uscita per le varie combinazioni di \(x\) e di \(S\), ottenendo i risultati in figura: quali differenze sono significative?
Senza un modello di riferimento
Senza un modello di riferimento che esprima \(v=f(x, S)\) non ha senso effettuare una regressione
Tuttavia posso riportare, per ogni trattamento
- il valor medio, unendo le serie con una spezzata al solo scopo di raggruppare visivamente i dati
- i limiti dell’intervallo di confidenza per ogni serie e per ogni trattamento
- oppure, unire i limiti con una banda che rappresenta la confidenza sulla media
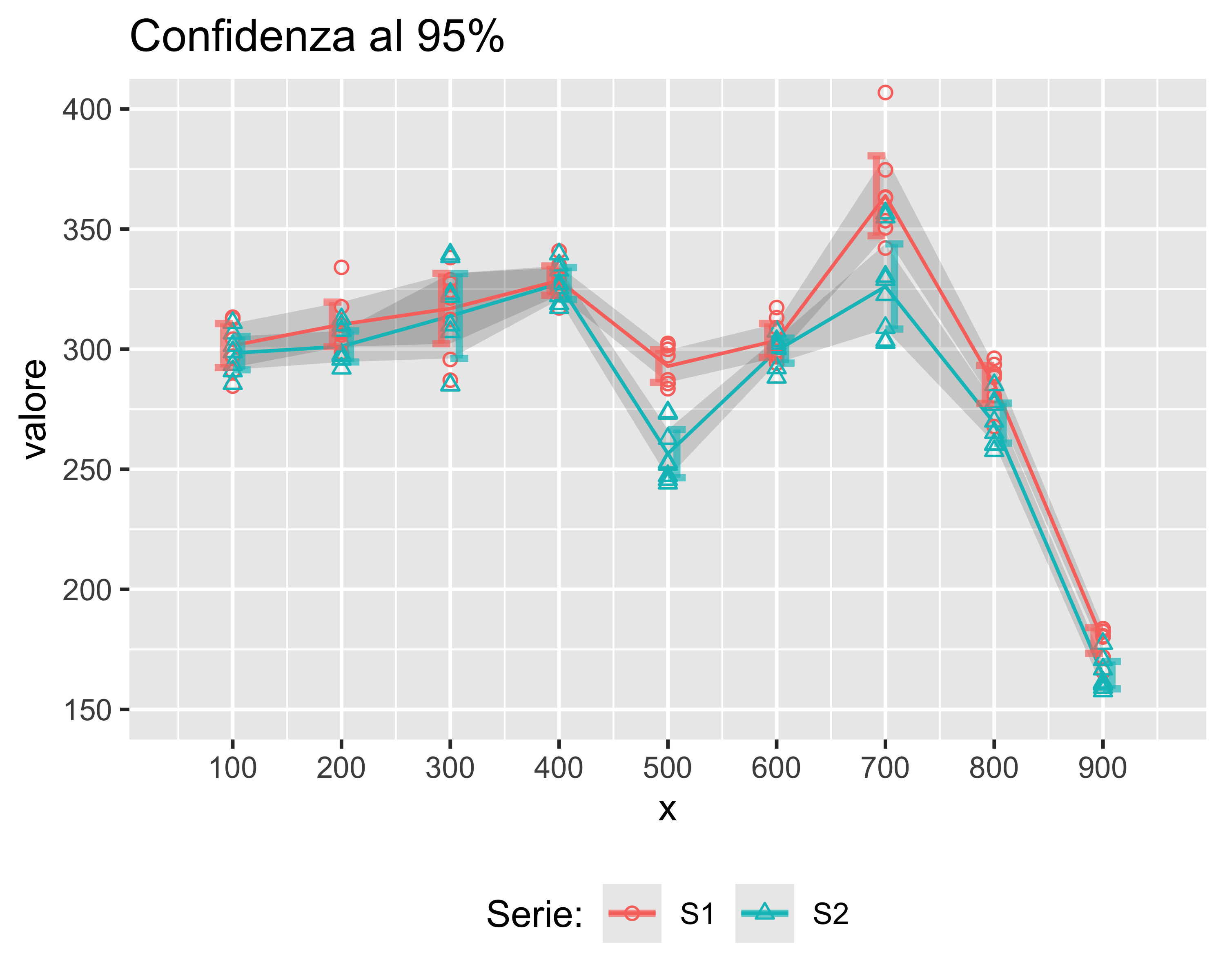
Zone in cui le bande sono sovrapposte sono statisticamente indistinguibili
Con un modello
Solo se ho un modello \(v=f(x, S)\) posso effettuare una regressione
Anche in questo caso, la regressione va accompagnata con bande di confidenza
Di nuovo, zone in cui le bande sono sovrapposte sono statisticamente indistinguibili